Entre los programadores de todo el mundo, los lenguajes de propósito general son los que mayor acogida encuentran porque permiten desarrollar proyectos de diferente perfil. R no lo es. Es una sintaxis que se utiliza para el tratamiento de grandes volúmenes de datos, normalmente de índole estadística, y con un único objetivo: visualizar para entender. Aún así, su uso se ha popularizado.
¿Por qué R se ha convertido en una opción tan interesante?
1. Lenguaje robusto.
R es un lenguaje con una curva de aprendizaje compleja, pero muy robusto y efectivo para el manejo de datos estadísticos. Es un lenguaje orientado a objetos, muy similar a las sintaxis C y C++. Para los desarrolladores especializados en estos lenguajes, puede ser sencillo. Además, R es un lenguaje de programación que está en constante evolución y del que se dispone de una amplia documentación.
2. Facilidad en la preparación de los datos.
Cuando un programador maneja volúmenes de datos muy elevados, gran parte del tiempo se dedica a preparar la información para la visualización de la que se pueden extraer conclusiones. Con R esa preparación es relativamente sencilla, en gran medida porque automatiza muchos procesos mediante la programación de scripts.
3. R funciona con cualquier tipo de archivo.
R es muy flexible, puede trabajar con datos procedentes de todo tipo de archivos: un .txt, un .csv, un JSON o un EXCEL…
4. Gestión de un gran volumen de datos.
R es un lenguaje que permite la implementación de paquetes adicionales que le dan una capacidad de gestión de datos enorme. En proyectos de gran volumen, la escalabilidad es un elemento clave.
5. Es de código abierto y gratuito.
Si eres programador y quieres empezar con R, esto es un detalle importante. No hay limitaciones. El código está en cualquier repositorio de plataformas de desarrollo colaborativo como GitHub o foros de dudas para desarrolladores como Stackoverflow. Hay librerías y paquetes adicionales para impulsar proyectos, cuyo código se puede modificar al gusto para implementar nuevas funcionalidades. Y gratis.
6. Visualizaciones: ¿quién lo va a entender si no hay gráficos?
Si hay algo que define a R es su capacidad para visualizar información compleja de una forma sencilla. Cualquier desarrollador dispone de librerías especializadas en visualización de datos para hacer gráficos.
¿Cómo empiezo a trabajar con datos gracias a R?
Para instalar R en nuestro ordenador, debemos acudir al proyecto CRAN (Comprehensive R Archive Network) y descargar el ejecutable para Linux, Mac OS X o Windows. Una vez descargado, el proceso es el habitual para cualquier programa o aplicación web instalada en un sistema operativo:
– Se ejecuta el archivo .exe. Si es la primera vez que instalamos R en nuestro equipo, no habrá problemas. Si dispone de una versión de R anterior instalada en la máquina, lo ideal es desinstalarla primero.
Después de escoger idioma, el usuario va avanzando en el proceso de instalación a través de diferentes pantallas.
– Es necesario escoger una carpeta para alojar R.
– Hay dos tipos de instalación: de usuario (la estándar) o completa.
En CRAN disponemos del listado completo de paquetes de R por orden alfabético. Encontramos código fuente y documentación. Cada paquete también incluye información sobre sus funcionalidades.
Como cualquier otra sintaxis, un desarrollador debe utilizar un Entorno de Desarrollo Integrado (IDE) para programar un proyecto. En el caso de R, uno de los más utilizados es RStudio. Este IDE dispone de una consola y un editor de texto, con algunas características como resaltado de sintaxis, depurador de errores, autocompletado de código, gestor avanzado de directorio de trabajo…
¿Cuáles son las mejores librerías para R?
1. Manipulación de datos
– plyr: este paquete de R permite hacer operaciones en los subgrupos de un gran conjunto de datos. Dispone de distintas funciones para operar con esos datos: ddply, daply, dlply, adply o ldply. ¿Cómo se podría empezar a trabajar con ella?
– Instalación: usar la función install.packages (“plyr”).
– Cargar la librería: utilizar el comando library (“plyr”).
– Cómo aplicar operaciones dentro de un conjunto de datos incluido dentro del paquete plyr de R: podemos utilizar datos estadísticos sobre jugadores de béisbol data (baseball) y comenzar a operar con ellos para, por ejemplo, saber el mínimo y el máximo de partidos de un jugador por año:
ddply(baseball, .(id), function(x) c(años=nrow(x), minimo=min(x$g), maximo=max(x$g)))
Este proceso de instalación y ejecución de paquetes en R es siempre el mismo para todos. Función install.packages para instalar el paquete y la función library para cargarlo.
– reshape2: este paquete de R permite la transformación de los datos entre los formatos Ancho (Wide) y Largo (Long). Está basado en dos funciones claves como melt y cast. Melt coge los datos en formato Wide y los convierte al formato Long. La función cast hace el mismo proceso, pero al revés.
Los datos en formato Wide tienen una columna por cada variable. El formato Long tiene una columna para cada uno de los tipos de variables y otra para los valores de esas variables. Las funciones del paquete reshape2 me permiten transformar un conjunto de datos de un formato a otro de una forma sencilla. Caso práctico.
Otros paquetes de R para la manipulación de datos: lubridate y stringr.
2. Visualización de datos
– ggplot2: es un paquete que proporciona a R todo lo necesario para hacer gráficos de una forma asequible. Es una librería realmente potente: permite todo tipo de visualizaciones (barras, puntos, líneas, áreas…); tiene sistema de coordenadas para hacer gráficos de mapas; o escalas. ggplot2 se puede combinar con otras librerías para crear, por ejemplo, tendencias con los datos.
ggplot2 no forma parte del paquete estándar de instalación de R. Por tanto, es necesario descargarlo e incluirlo de forma específica. Ya descargado, hay dos funciones para instalar y ejecutar:
– Función install.packages (“ggplot2”) para instalarlo.
– Y usamos la función library (“ggplot2”) para cargarlo.
El paquete de R ggplot2 depende de otros paquetes que también deben estar descargados e instalados como ‘itertools’, ‘iterators’, ‘reshape’, ‘proto’, ‘plyr’, ‘RColorBrewer’, ’digest’ y ‘colorspace’.
– rgl: paquete para la creación de gráficos en 3D en tiempo real. Utiliza un backend de renderizado OpenGL (Open Graphics Library, una especificación estándar que define un conjunto de funciones para escribir aplicaciones de visualización de datos).
3. Aprendizaje automático
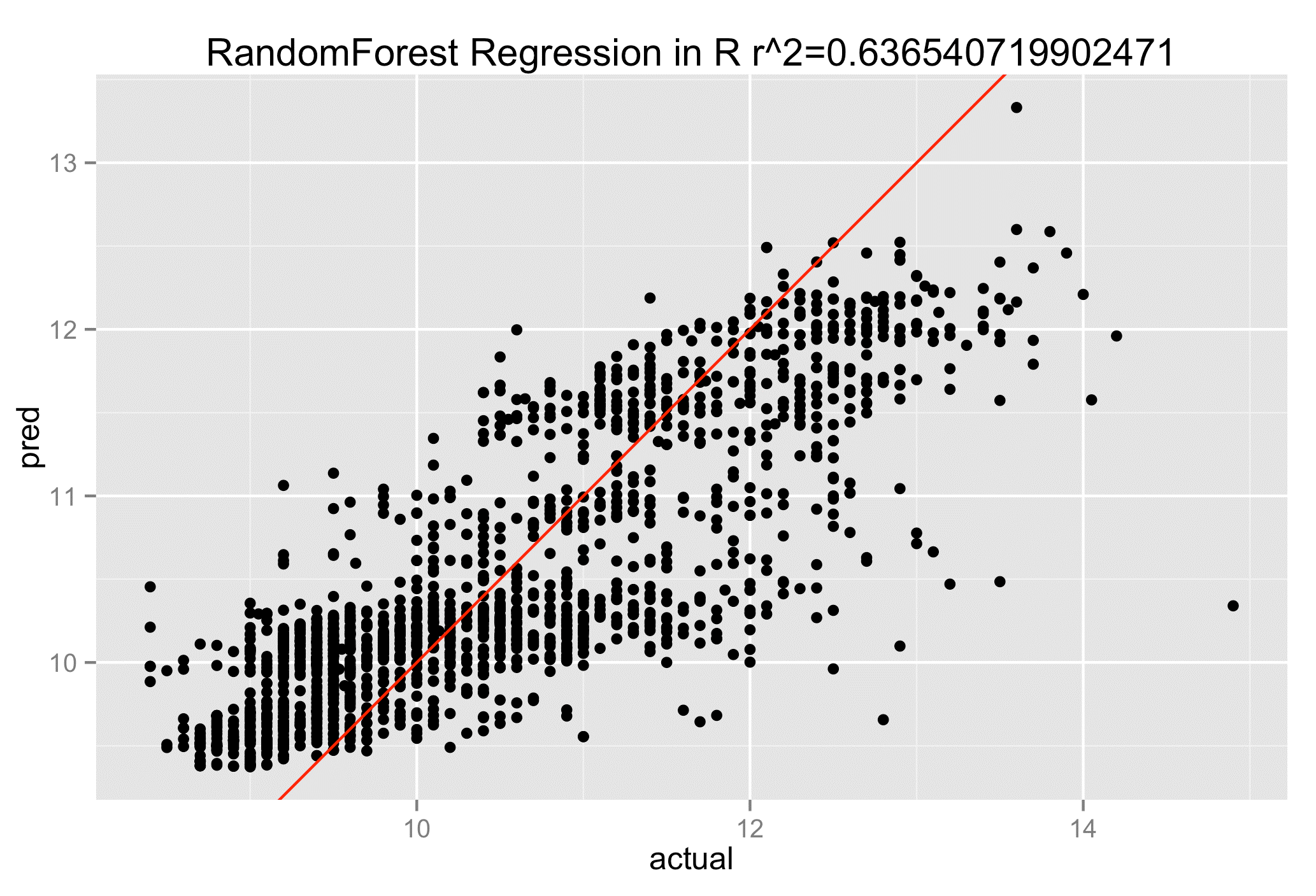
– randomforest: es un método de clasificación mediante el uso de árboles de decisión (una técnica de machine learning estándar) aplicado a grandes volúmenes de datos. Se puede usar tanto en el aprendizaje supervisado como en el no supervisado.
Este método tiene algunas características importantes:
– Método eficiente en grandes bases de datos.
– Permite la gestión de miles de variables de entrada sin que sea necesario el borrado de variables.
– Los árboles de decisión creados en un proyecto pueden ser utilizados para otros conjuntos de datos en un futuro.
– Dispone de una función de estimación de datos faltantes. Eso permite que el método mantenga su precisión aunque haya datos a los que no se tenga acceso.
– randomForestSRC: método de bosques aleatorios de supervivencia, regresión y clasificación.
El bosque aleatorio de supervivencia es una herramienta matemática que permite ponderar un gran número de variables para generar un modelo predictivo de supervivencia, normalmente utilizado dentro del sector de la salud.
Los árboles de clasificación se utilizan cuando la variable de respuesta o de destino es categórica. En cambio, los árboles de regresión se usan cuando la variable respuesta es numérica. Es la diferencia entre un modelo de clasificación o de predicción.
Existen otros paquetes de R muy utilizados entre los científicos de datos:
– Gradient boosting: gbm y xgboost.
– Máquinas de soporte de vectores: e1071, LiblineaR y kernlab.
– Regresión con regularización: glmnet.
– Modelos generalizados aditivos: gam.
– Clustering: cluster.
Síguenos en @BBVAAPIMarket