En el post anterior, comenzamos a ver algunos ejemplos de SQL geoespacial, operando con datos reales, relativos a Colombia, y cargados en CartoDB. En este post, continuaremos viendo consultas SQL espaciales y algunos sencillos ejemplos de análisis espacial mediante lenguaje SQL.
SQL geoespacial y funciones agregadas
El uso de las relaciones espaciales junto con funciones de agregación y la cláusula de agrupamiento group by, permite operaciones muy poderosas con nuestros datos. Veamos un ejemplo sencillo: El número de escuelas que hay en cada uno de los barrios de Bogota.
Para ello, como hicimos en el post anterior, entraremos en la consola SQL disponible en nuestro dashboard, para la tabla de barrios_de_bogota, y ejecutaremos la siguiente consulta SQL.
SELECT b.name, count(p.type) as hospitals FROM barrios_de_bogota b JOIN
points p on st_contains(b.geom, p.geom) WHERE p.type = 'hospital'
GROUP BY b.name ORDER BY hospitals desc
Como resultado, obtenemos la lista de barrios, junto con el número de escuelas en dicho barrio, ordenados de mayor a menor número de escuelas.
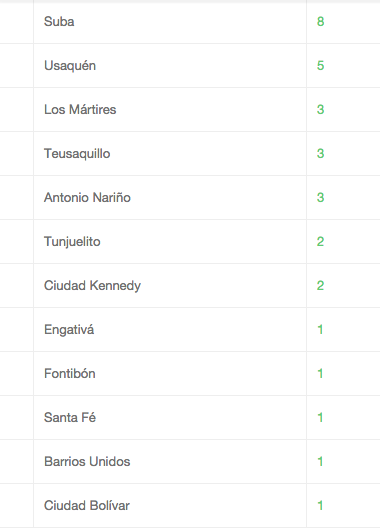
De manera resumida, las operaciones que realiza esta consulta son:
1. La clausula JOIN crea una tabla virtual que incluye los datos de los barrios y de los puntos de interés
2. WHERE filtra la tabla virtual solo para las columnas en las que el punto de interés es un hospital
3. Las filas resultantes son agrupadas por el nombre del barrio y rellenadas con la función de agregación COUNT().
Análisis geoespacial en CartoDB
Como ya hemos mencionado, el uso de las funciones espaciales de PostGIS en unión con las funciones de agregación de PostgreSQL supone un binomio muy potente. Además, nos da la posibilidad de realizar análisis espaciales de datos agregados. Como ejemplo, vamos a ver la estimación proporcional de datos censales, usando como criterio la distancia entre elementos espaciales.
Este ejemplo está basado en un ejemplo similar presentado en el libro PostGIS Cookbook. Un manual de referencia recomendado para usuarios medios / avanzados de PostGIS.
Tomemos como base los datos vectoriales de los barrios de Bogotá y los datos vectoriales de vías de ferrocarril (tablas barrios_de_bogota y railways, respectivamente). Para poder visualizar dos capas (tablas) simultáneamente, pulsamos en la opción de Add Layer, en la parte superior de la barra lateral derecha

Elegimos como capa la tabla railways
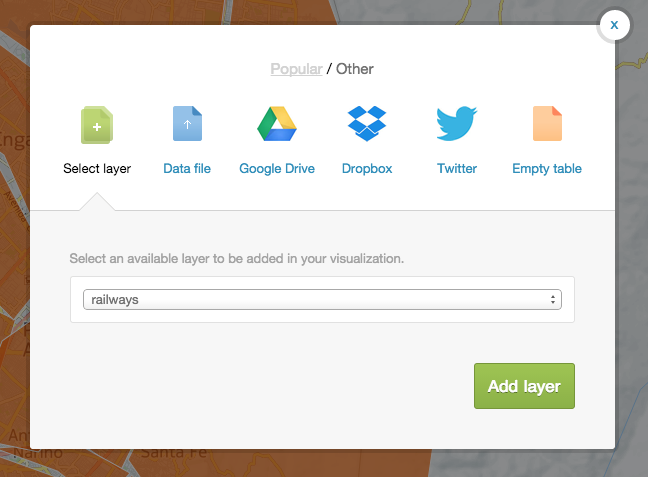
Al ir a mostrar más de una capa al mismo tiempo, CartoDB nos pedirá construir una visualización. Aceptamos, y le ponemos un nombre. Ya podremos ver las dos capas al mismo tiempo.
Fijémonos ahora en una línea de ferrocarril que cruza 3 barrios (Fontibón, Puente Aranda y Los Mártires)
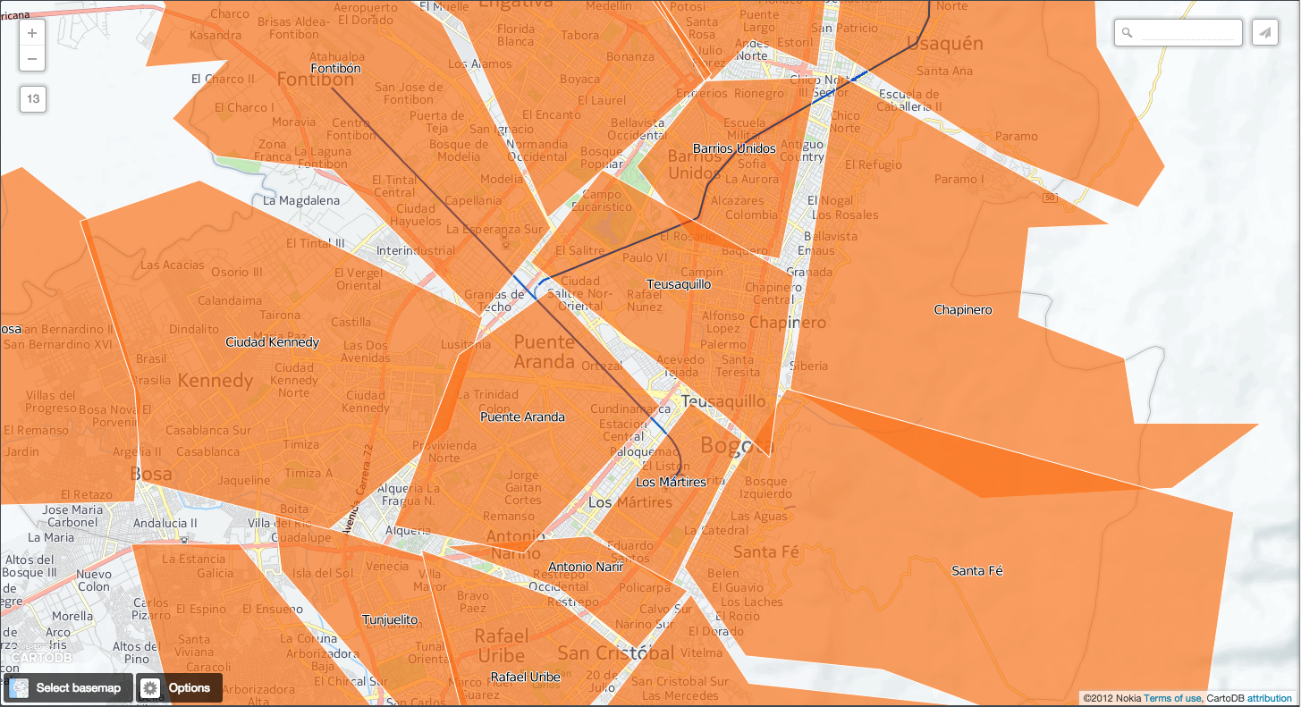
Construyamos ahora un buffer de 1km alrededor de dicha línea de ferrocarril. Es de esperar que las personas que usen la línea sean las que vivan a una distancia razonable. Para ello, debemos salir de la visualización y volver a la tabla barrios_de_bogota. A continuación, desde la consola SQL de dicha tabla, ejecutaremos la siguiente consulta.
SELECT
1 as gid,
ST_Transform(ST_Buffer(
(SELECT ST_Transform(the_geom, 21818) FROM railways WHERE gid = 2), 1000, 'endcap=round join=round'), 4326) as the_geom
Revisar la documentación de la función ST_Transform para entender los parámetros utilizados. Como ya vimos en el anterior post, hemos usado esta función para poder especificar las distancias en metros (en este caso, crear un buffer de 1km alrededor de la línea que representa la vía de tren).
Como resultados de esta consulta, veremos una única fila y, muy importante, la opción de crear una tabla a partir de este resultado.

Pulsamos en la opción create table from query, y le damos un nombre. En nuestro caso, railway_buffer. Ya estamos listos para crear una nueva visualización, esta vez, añadiendo otras dos capas. Lo haremos de la misma forma que añadimos la capa railways anteriormente, pero añadiremos las capas railways y railway_buffer.
Si superponemos la tabla creada sobre las provincias, podemos ver lo siguiente.
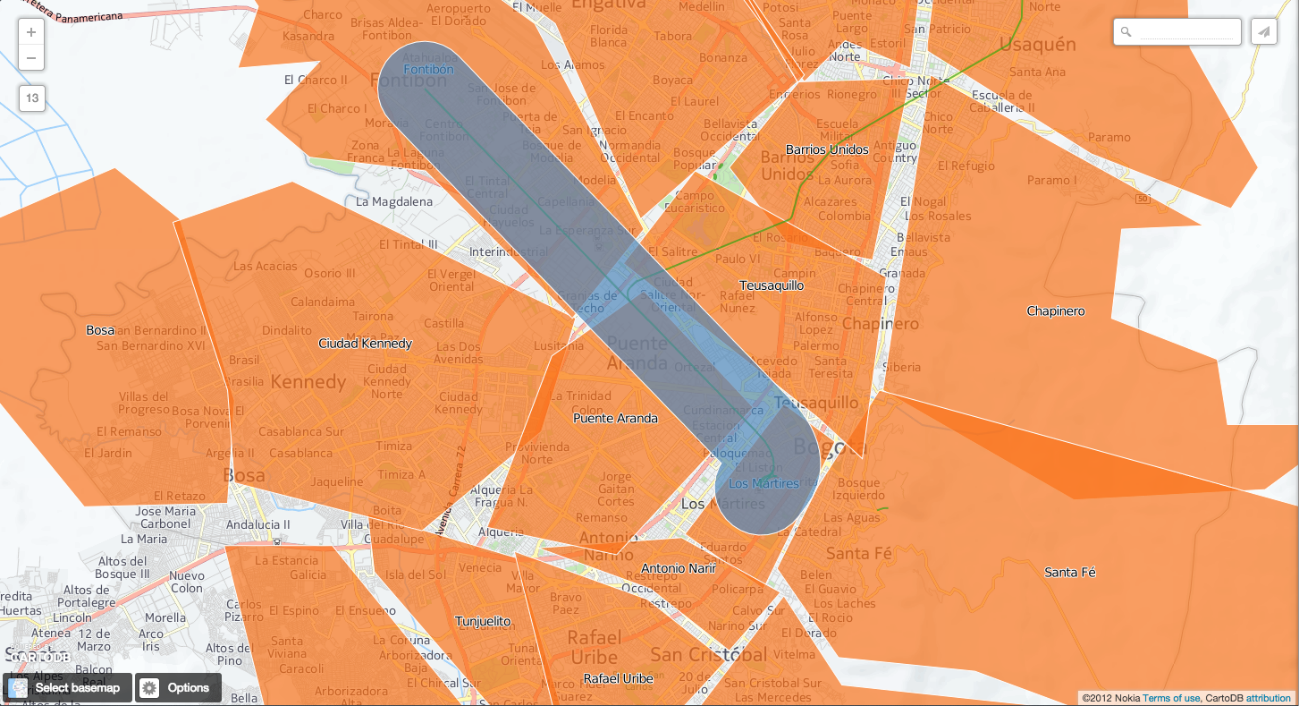
Como se observa, hay 4 barrios que intersectan con ese buffer. Los tres anteriormente mencionados y Teusaquillo.
Una primera aproximación para saber la población potencial que usará el ferrocarril sería simplemente sumar las poblaciones de los barrios que el buffer intersecta. Para ello, usamos la siguiente consulta espacial:
SELECT SUM(b.population) as pop
FROM barrios_de_bogota b JOIN railway_buffer r
ON ST_Intersects(b.the_geom, r.the_geom)
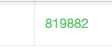
Esta primera aproximación nos da un resultado de 819892 personas.
No obstante, mirando la forma de los barrios, podemos apreciar que estamos sobreestimando la población, si utilizamos la de cada barrio completo. De igual forma, si contáramos solo los barrios cuyos centroides intersectan el buffer, probablemente infraestimaríamos el resultado.
En lugar de esto, podemos asumir que la población estará distribuida de manera más o menos homogénea (esto no deja de ser una aproximación, pero más precisa que lo que tenemos hasta ahora). De manera que, si el 50% del polígono que representa a un barrio está dentro del área de influencia (1 km alrededor de la vía), podemos aceptar que el 50% de la población de ese barrio serán potenciales usuarios del ferrocarril. Sumando estas cantidades para todos los barrios involucrados, obtendremos una estimación algo más precisa. Habremos realizado una suma proporcional.
Para realizar esta operación, vamos a construir una función en PL/pgSQL. Esta función la podremos llamar en una query, igual que cualquier función espacial de PostGIS. Copiaremos este código en la consola SQL de nuestra tabla barrios_de_bogota, como viene siendo habitual.
CREATE OR REPLACE FUNCTION public.proportional_sum(geometry, geometry, numeric)
RETURNS numeric AS
$BODY$
SELECT $3 * areacalc FROM
(
SELECT (ST_Area(ST_Intersection($1, $2))/ST_Area($2))::numeric AS areacalc
) AS areac;
$BODY$
LANGUAGE sql VOLATILE
Esta función toma como argumentos las dos geometrías a intersectar y el valor total de población del cuál queremos estimar la población proporcional que usará el tren. Devuelve el número con la estimación. La operación que hace es simplemente multiplicar la proporción en la que los barrios se solapan con la zona de interés por la cantidad a proporcionar (la población).
La llamada a la función es como sigue:
SELECT ROUND(SUM(proportional_sum(a.the_geom, b.the_geom, b.population))) FROM
railway_buffer a, barrios_de_bogota b
WHERE ST_Intersects(a.the_geom, b.the_geom)
GROUP BY a.cartodb_id
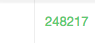
En este caso, el resultado obtenido es 248217, que parece más razonable.
Con este ejercicio, damos por finalizada nuestra serie de posts acerca de SQL geoespacial. En el primer post de la serie, realizamos una introducción teórica a los predicados espaciales y al concepto de índice geoespacial. En el segundo post, vimos una serie de ejemplos sencillos usando dichos predicados, y unos datos geográficos específicos pertenecientes a Colombia. En este tercer post, hemos visto el uso de funciones agregadas aplicadas a las consultas espaciales, y un sencillo ejercicio de análisis espacial. Para todos los ejemplos, hemos usado CartoDB, la manera más sencilla de utilizar una base de datos espacial sin necesidad de instalar software en nuestras máquinas.
























