To work with data, it is essential to have data. Sometimes that information is structured and on other occasions it is unstructured. Nowadays there are many tools or processes through which a developer can extract data from complex formats such as PDF or one or more websites, which is known as web scraping. The goal is to have the data to be able to view and understand.
Web scraping could be defined as the technique by which a team of developers is able to scrape or free data from websites run by governments, state institutions and organizations to access private or public data that may be published or distributed in open format. The problem is that the format of most interesting data is not reusable and it is opaque such as a PDF for example.
In order to access and distribute this information, there are a lot of tools or processes through the use of programming languages. This is a guide to using the main data extraction methods.
Web scraping tools
● ImportHTML formula
As part of Google applications, the grand search engine has developed its own Excel called Google Spreadsheet. This tool provides almost all the features offered by Microsoft Excel, but also has some added functionality through content that is indexed to the internet by the search engine: RSS feed reader, website updates and data extraction.
All this is possible through the use of formulas like ImportFeed, ImportHTML and ImportXML. The second of these allows any user to extract data from tables or lists in an orderly fashion from any website. One of the elements of the formula type varies depending on whether it is a table or a list. Here are two practical examples:
=ImportHTML(“url página web”, “table”, 2)
=ImportHTML(“url página web”, “list”, 2)
By including any of these formulas in the first cell of Google Spreadsheet, it possible to extract the second table or list of the URL that the user adds within double quotes. It is very simple.
Table Capture is an extension for the Chrome browser, which provides a user with data on a website with little difficulty. It extracts the information contained in an HTML table of a website to any data processing format such as Google Spreadsheet, Excel or CSV. This is similar to the ImportHTML formula.
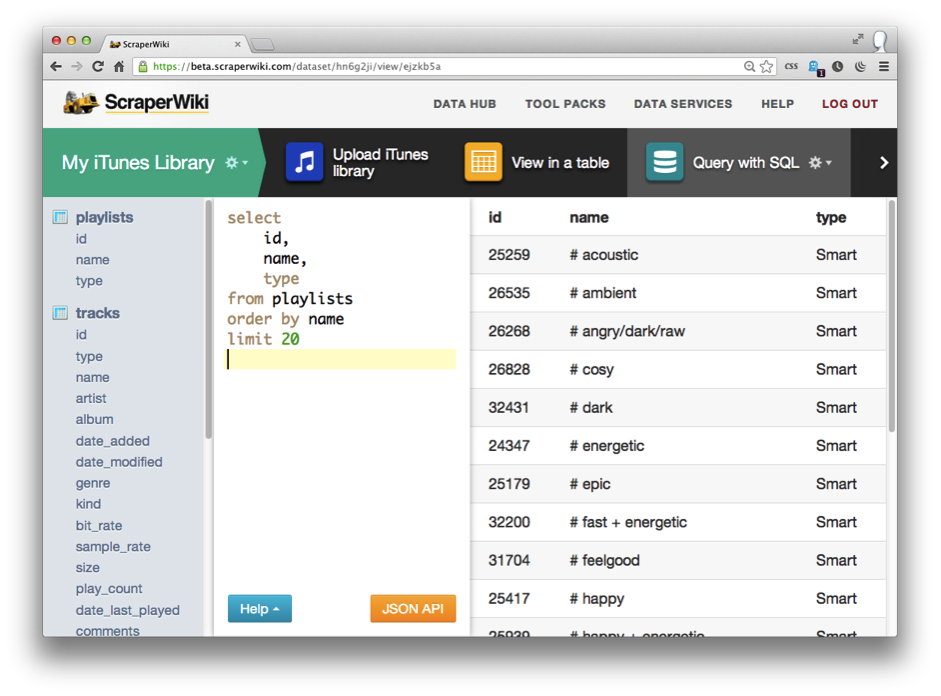
ScraperWiki is the perfect tool for extracting data arranged in tables in a PDF. All you need to do is load the file and export it. If the PDF has multiple pages and numerous tables, ScraperWiki provides a preview of all the pages and the various tables and the ability to download the data in an orderly way and separately.
With ScraperWiki you can also clean the data before it is exported to a Microsoft Excel file. This is useful as it makes things much easier when clean data is added to a visualization tool.
Tabula is a desktop application for Windows, Mac OSX and Linux computers that provides developers and researchers with a simple method to extract data from a PDF to a CSV or Microsoft Excel file for editing and viewing. Tabula is a tool that is widely used in data journalism.
The steps to use Tabula are as follows:
– Load a PDF with the data table you want to export.
– Select the table with all the information.
– Select the option ‘Preview and data extraction’. Tabula scrapes the data in the table and provides the user with a preview of the information extracted for it to be checked.
– Click ‘Export’.
– The data are exported to a Microsoft Excel file, or a LibreOffice file if you do not have Microsoft Office.
Import.io is a free online tool, but there is also a fee-based version for companies. This aids structured extraction of data and downloading in CSV format or generating an API with the information. API data are updated as data is modified in the source environment.
Import.io has a desktop application that can be downloaded by any user to their Windows, Mac OSX or Linux computer. In this application, Import.io offers several methods for extracting very different data: information contained in a URL, information in HTML or XML, images, numerical values, maps, i.e. everything.
Extracting data with Python
In BBVAOpen4U we have seen what Python is and how it works when developing digital projects or using libraries for data visualization, but this is the first time one of its most interesting and professional features has been mentioned: extracting unstructured data. There are also many libraries in this language for data access.
BeautifulSoup is a Python library used to easily extract specific data from a web page in HTML without much programming. It is technically called parsing HTML. One of the advantages of this library in Python is that all of the output documents of the data extraction are created in UTF-8, which is quite interesting because the typical problem of encoding is completely solved.
Another powerful feature of BeautifulSoup is that it uses Python analyzers such as lxml or html5lib, which makes it possible to crawl tree-structured websites. These enable you to go through each ‘room’ of a website, open it, extract your information and print it.
Scrapy is an open code development framework for data extraction with Python. This framework allows developers to program spiders used to track and extract specific information from one or several websites at once. The mechanism used is called selectors; however, you can also use libraries in Python such as BeautifulSoup or lxml.
In the dynamic world of payments, a new star has emerged in recent years: Buy Now Pay Later (BNPL), i.e. short-term financing that allows you to buy now and pay later. This model allows businesses to purchase goods or services and pay for them in installments, often interest-free, making it an attractive alternative to credit […]
BBVA and Vecttor, Cabify’s subsidiary engaged in managing vehicles with drivers, have entered into an alliance that saves time and provides security to the company and its drivers. The collaboration allows drivers to deposit cash collections at any BBVA ATM and Vecttor to automatically reconcile this activity from their accounts with those in the company’s […]
BBVA has been recognized by Global Finance as the bank with the best global open banking offer for companies. This award comes on top of 12 other recognitions the magazine has bestowed on the company, such as the best bank for corporate clients and the one recognizing its AI factory as one of the best […]
Please, if you can't find it, check your spam folder
×
The email message with your ebook is on the way
We have sent you two messages. One with the requested ebook and one to confirm your email address and start receiving the newsletter and/or other commercial communications from BBVA API_Market
×
PROCESSING OF PERSONAL DATA
Who is the Data Controller of your personal data?
Banco Bilbao Vizcaya Argentaria, S.A. (“BBVA“) with registered address at Plaza de San Nicolás 4, 48005, Bilbao, España and Tax ID number A-48265169 . Email address: contact.bbvaapimarket@bbva.com
What for and why does BBVA use your personal data for?
For those activities among the following for which you give your consent by checking the corresponding box:
to receive newsletter from BBVA API_Market through electronic means;
to send you commercial communications, events and surveys relating to BBVA API_Market to the e-mail address you have provided.
For how long we will keep your data?
We will keep your data until you unsubscribe from receiving our newsletter or, if applicable, the commercial communications, events and surveys to which you have subscribed. Whether you unsubscribe or whether BBVA decides to end the service, your details will be deleted.
How can I unsubscribe to stop receiving newsletters and/or communications from BBVA API_Market?
You can unsubscribe at any time and without need to indicate any justification, by sending an email to the following address: contact.bbvaapimarket@bbva.com
To whom will we communicate your data?
We will not transfer your personal data to third parties, unless it is mandatory by a law or if you have previously agreed to do so.
What are your rights when you provide us with your information?
You will be able to consult your personal data included in BBVA files (access right)
You can modify your personal data when they are inaccurate (correction right)
You may request that your personal data not be processed (opposition right)
You may request your personal data be deleted (suppression right)
You can request a limitation on the processing of your data in the allowed cases (right of limitation of processing)
You will be able to receive, in electronic format, the personal data you have provided to us, as well as to transmit them to another entity (portability right)
You are responsible for the accuracy of the personal data you provide to BBVA and to keep them duly updated. If you believe that we have not processed your personal data in accordance with regulations, you can contact the Data Protection Officer of BBVA at the following address dpogrupobbva@bbva.com.
You can find more information in the “Personal Data Protection Policy” document on this website.
×
PROCESSING OF PERSONAL DATA
Who is the Data Controller of your personal data? Banco Bilbao Vizcaya Argentaria, S.A (“BBVA“), with registered address at Plaza de San Nicolás 4, 48005, Bilbao, España, and Tax ID No. A-48265169. Email address:contact.bbvaapimarket@bbva.com
What for and why does BBVA use your personal data for?
For the execution and management of your request, specifically, download the requested e-book/s.
BBVA informs you that, unless you indicate your opposition by sending an email to the following address: contact.bbvaapimarket@bbva.com, BBVA may send you commercial communications, surveys and events related to products and/or services of BBVA API Market through electronic means.
For how long we will keep your data?
We will keep your data as long as necessary for the management of your request, and to receive commercial communications, events and surveys. BBVA will keep your data until you unsubscribe to stop receiving our newsletters or, where appropriate, until the end of the service. Afterwards, we will destroy your data.
How can I unsubscribe to stop receiving newsletters and/or communications from BBVA API Market?
You can unsubscribe at any time and without need to indicate any justification, by sending an email to the following address: contact.bbvaapimarket@bbva.com
To whom will we communicate your data?
We will not transfer your personal data to third parties, unless it is mandatory by a law or if you have previously agreed to do so.
What are your rights when you provide us with your information?
You will be able to consult your personal data included in BBVA files (access right)
You can modify your personal data when they are inaccurate (correction right)
You may request that your personal data not be processed (opposition right)
You may request your personal data be deleted (suppression right)
You can request a limitation on the processing of your data in the allowed cases (right of limitation of processing)
You will be able to receive, in electronic format, the personal data you have provided to us, as well as to transmit them to another entity (portability right)
You can exercise before BBVA the aforementioned rights through the following address: contact.bbvaapimarket@bbva.com
You are responsible for the accuracy of the personal data you provide to BBVA and to keep them duly updated.
If you believe that we have not processed your personal data in accordance with the regulations, you can contact the Data Protection Officer at the following address: dpogrupobbva@bbva.com
You can find more information in the “Personal Data Protection Policy” document on this website.
Banco Bilbao Vizcaya Argentaria, S.A. owner of this portal uses cookies and/or similar technologies of its own and third parties for the purposes of personalization, analytics, behavioral advertising or advertising related to your preferences based on a profile prepared from your browsing habits (e.g. pages visited). If you wish to obtain more detailed information, consult our Cookies Policy.
Cookie settings panel
These are the advanced settings for first-party and third-party cookies. Here you can change the parameters that will affect your browsing experience on this website.
Technical Cookies (required)
These cookies are used to give you secure access to areas with personal information and to identify you when you log in.
Name
Owner
Duration
Description
gobp.lang
BBVA
1 month
Language preference
aceptarCookies
BBVA
1 year
Configuration Accepted Cookies
_abck
BBVA
1 year
Helps protect against malicious website attacks
bm_sz
BBVA
4 hours
Helps protect against malicious website attacks
ADRUM_BTs
Salesforce Marketing Cloud
Session
Required for monitoring of the service, inherent to SFMC
ADRUM_BT1
Salesforce Marketing Cloud
Session
Required for monitoring of the service, inherent to SFMC
ADRUM_BTa
Salesforce Marketing Cloud
Session
Required for monitoring of the service, inherent to SFMC
ADRUM_BT
Salesforce Marketing Cloud
Session
Required for monitoring of the service, inherent to SFMC
xt_0d95e
Salesforce Marketing Cloud
Session
Remember user preferences (if any)
__s9744cdb192d044faa1bf201d29fafd1e
Salesforce Marketing Cloud
Session
Remember user preferences (if any)
wpml_browser_redirect_test
WPML
Session
Text translation in the portal
wp-wpml_current_language
WPML
24 hours
Text translation in the portal
They are used to track the activity or number of visits anonymously. Thanks to them we can constantly improve your browsing experience
Your browsing experience is constantly improving.
With your selection, we cannot offer you a continuously improved browsing experience.
Name
Owner
Duration
Description
AMCV_***
Adobe Analytics
Session
Unique Visitor IDs used in Cloud Marketing solutions
AMCVS_***
Adobe Analytics
2 years
Unique Visitor IDs used in Cloud Marketing solutions
demdex (safari)
Adobe Analytics
180 days
Create and store unique and persistent identifiers
sessionID
Adobe Analytics
Session
Launch's internal cookie used to identify the user
gpv_URL
Adobe Analytics
Session
Adobe Analytics plugin: getPreviousValue Capture the value of a certain variable in the following page view, in this case the prop1
gpv_level1
Adobe Analytics
Session
Cookie used to store the DataLayer levl1 of the previous page.
gpv_pageIntent
Adobe Analytics
Session
Cookie used to store the pageIntent of the previous page.
gpv_pageName
Adobe Analytics
Session
Cookie used to store the pagename of the previous page.
aocs
Adobe Analytics
Session
Cookie that stores the first values collected at the beginning of a process.
TTC
Adobe Analytics
Session
Cookie used to store the time between the App Page Visit event and the App Completed event.
TTCL
Adobe Analytics
Session
Cookie used to store the time between the LogIn event and App Completed.
s_cc
Adobe Analytics
Session
Determine if cookies are active
s_hc
Adobe Analytics
Session
Cookie used by Adobe for analytical purposes
s_ht
Adobe Analytics
Session
Cookie used by Adobe for analytical purposes
s_nr
Adobe Analytics
2 years
Determine the number of user visits
s_ppv
Adobe Analytics
Permanent
Adobe Analytics plugin: getPercentPageViewed Determine what percentage of the page a user views
s_sq
Adobe Analytics
Session
ClickMap/ActivityMap features
s_tp
Adobe Analytics
Session
Cookie used by Adobe for analytical purposes
s_visit
Adobe Analytics
2 years
Cookie used by Adobe to know when a session has been started.
They allow the advertising shown to you to be customized and relevant to you. Thanks to these cookies, you will not see ads that you are not interested in.
The advertising is customized to you and your preferences.
Your choice means you will not see customized ads, only generic ones.
Name
Owner
Duration
Description
OT2
VersaTag
90 days
VersaTag Cookie used to store a user id and the number of user visits.
u2
VersaTag
90 days
VersaTag Cookie where the user ID is stored
TargetingInfo 2
MediaMind
1 year
Cookie that serves to assign a unique random number that generates MediaMind.
These cookies are related to general features such as the browser you use.
Your experience and content have been customized.
With your selection, we cannot offer you a continuously improved browsing experience.
Name
Owner
Duration
Description
mbox
Adobe Target
9 days
Cookie used by Adobe Target to test user experience customization.
×
Looks like you’re browsing from MexicoSpainArgentinaPeruColombiaBelgiumChileUSAFranceHong KongItalyPortugalUnited KingdomTurkeyUruguayVenezuelaAlemania, so let’s show you the custom content for your
location. Change
Select a country
In order to access the private area and corresponding sandbox, select the country of the APIs you want to use.