The big crystal ball to read the present and anticipate the future. This has what automatic learning, or machine learning has turned into, with a touch of fantasy. The large-scale use of data to create predictive models that perfect themselves on their own as they obtain results from their predictions. A type of artificial intelligence that learns by itself and gives business guidelines in sectors such as banking, technology and energy.
The companies that offer machine learning services have also understood, almost better than anyone else, that the development of their APIs and their use are a huge support for companies that want to begin implementing automatic learning processes in their strategic decisions. They make it possible to do things in days that used to take weeks. Not just companies such as BigML, which has its API RESTBigML.io, but also giants such as Google, Amazon and IBM have them.
BigML, a Spanish-American startup
BigML.io is an API REST to easily develop and apply predictive models to the projects of any company. It’s a very flexible application development interface: it can be used to implement supervised and unsupervised automatic learning tasks and to create all the processes required for a more complex machine learning system. With BigML.io, you can say that any company has the easiest predictive models, but also the most complex, within the scope of its development equipment. The BigML API REST is always used with standard HTTP methods.
What can be done with BigML.io?
– Real time predictions.
– Access to anomaly databases, models and detectors.
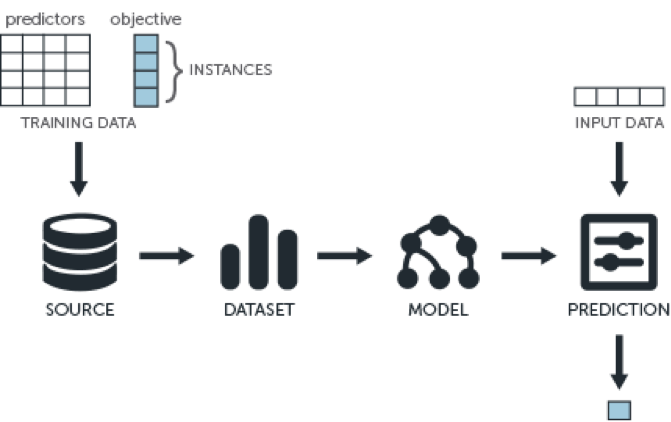
– Use of the BigML resources through programming. There are four types of resources: source, dataset, model and prediction. The normal flow in the use of BigML.io is the use of training data to create a source, which would constitute a dataset to create a model. This model, which has a constant data input, is used to establish the predictions.
The training data of the future model normally comes in a table. Each row is an instance or example of each column, a field or attribute. These fields are also called predictors or co-variables. Within an automatic learning process, one of the columns, normally the last, represents a special attribute called objective or destination field, which assigns a label or type for each instance (dataset row). In these types of cases, there is a labeled dataset and a supervised learning process.
The idea is that one data source can create several datasets. In turn, a dataset can generate various model and one unique model, various predictions. If the objective field is a category, we are looking at a classification model. If it’s a number, it’s a regression model. Within automatic learning, the processes that include a dataset are the best, because this increases its efficiency.
If there is a dataset without an objective field, we would be looking at an un supervised learning process, with non-tagged data (without labels). These types of datasets are normally used to create anomaly detectors. Whilst the models make predictions, the anomaly detectors rate anomalies. This increases the efficiency of the model’s predictions.
Large companies also have machine learning APIs
Google is known as the search giant, but that definition began to fall short a few years ago. The company Mountain View also has an application development interface to make predictions called Google Prediction API. Predictions that can anticipate the bad status of a company or a startup and discover possible solutions for specific problems.
This Google interface is an API RESTful, which works asynchronously and is based in the cloud. It also enables developers to incorporate training datasets on the fly to develop the predictive model. In which fields of business does Google Prediction API work?:
– Customer sentiment analysis.
– Recommendation systems.
– Spam detection.
– Sales opportunity analysis.
– Identification of fraud or suspicious activities.
These are two interesting tutorials for using the API to create services for clients and detecting fraud in the health field:
Another large company that has spent a lot of time in the automatic learning field, and very successfully at that, is IBM. It’s star product is IBM Watson, the artificial intelligence platform that uses cognitive computing and machine learning to make predictions for other companies in fields such as data or natural language processing This is why is has various APIs and SDKs in Node, Java, Python, for iOS operating systems and also for Unity.
– API for functionalities such as language: this API is used to develop applications that are able to understand language, extract value and knowledge from the work and improve its performance over time.
A third large company that has automatic learning APIs is Amazon, specifically Amazon Machine Learning API. The interface facilitates the development of predictive applications and hosts them in the cloud with Amazon Web Services. The full package. The development teams have viewing wizards and tools to create models without having to implement prediction generation codes or administer infrastructures.
Amazon Machine Learning API gives companies that use it for the daily management of their business model very important competitive advantages:
– Fraud detection.
– Content personalization.
– Propensity models for marketing campaigns.
– Document classification.
– Client renewal prediction.
– Recommendation of solutions for customer support services.
If you are interested in the world of APIs, find out more about BBVA’s APIs here.
The cash flow and payment management departments must consider the way in which payments to suppliers are made, because each type of payment has its own advantages or is better suited to the company’s strategy, the relationship with the supplier, or the respective needs of both. Far from being a trivial matter, choosing the payment […]
Businesses, from self-employed to SMEs and large companies, need financing solutions that suit their needs. Leasing is a method that can optimize the use of resources and which combines business liquidity (or lack of) with the use of assets. What is leasing and how does it work? Leasing is a financing method by which a […]
An API is a very useful mechanism that connects two pieces of software equipment to exchange messages or data in a standard format such as XML or JSON. Thus, it becomes an instrument that can be used to search for revenue, open the doors to talent or innovate and automate processes.
Please, if you can't find it, check your spam folder
×
The email message with your ebook is on the way
We have sent you two messages. One with the requested ebook and one to confirm your email address and start receiving the newsletter and/or other commercial communications from BBVA API_Market
×
PROCESSING OF PERSONAL DATA
Who is the Data Controller of your personal data?
Banco Bilbao Vizcaya Argentaria, S.A. (“BBVA“) with registered address at Plaza de San Nicolás 4, 48005, Bilbao, España and Tax ID number A-48265169 . Email address: contact.bbvaapimarket@bbva.com
What for and why does BBVA use your personal data for?
For those activities among the following for which you give your consent by checking the corresponding box:
to receive newsletter from BBVA API_Market through electronic means;
to send you commercial communications, events and surveys relating to BBVA API_Market to the e-mail address you have provided.
For how long we will keep your data?
We will keep your data until you unsubscribe from receiving our newsletter or, if applicable, the commercial communications, events and surveys to which you have subscribed. Whether you unsubscribe or whether BBVA decides to end the service, your details will be deleted.
How can I unsubscribe to stop receiving newsletters and/or communications from BBVA API_Market?
You can unsubscribe at any time and without need to indicate any justification, by sending an email to the following address: contact.bbvaapimarket@bbva.com
To whom will we communicate your data?
We will not transfer your personal data to third parties, unless it is mandatory by a law or if you have previously agreed to do so.
What are your rights when you provide us with your information?
You will be able to consult your personal data included in BBVA files (access right)
You can modify your personal data when they are inaccurate (correction right)
You may request that your personal data not be processed (opposition right)
You may request your personal data be deleted (suppression right)
You can request a limitation on the processing of your data in the allowed cases (right of limitation of processing)
You will be able to receive, in electronic format, the personal data you have provided to us, as well as to transmit them to another entity (portability right)
You are responsible for the accuracy of the personal data you provide to BBVA and to keep them duly updated. If you believe that we have not processed your personal data in accordance with regulations, you can contact the Data Protection Officer of BBVA at the following address dpogrupobbva@bbva.com.
You can find more information in the “Personal Data Protection Policy” document on this website.
×
PROCESSING OF PERSONAL DATA
Who is the Data Controller of your personal data? Banco Bilbao Vizcaya Argentaria, S.A (“BBVA“), with registered address at Plaza de San Nicolás 4, 48005, Bilbao, España, and Tax ID No. A-48265169. Email address:contact.bbvaapimarket@bbva.com
What for and why does BBVA use your personal data for?
For the execution and management of your request, specifically, download the requested e-book/s.
BBVA informs you that, unless you indicate your opposition by sending an email to the following address: contact.bbvaapimarket@bbva.com, BBVA may send you commercial communications, surveys and events related to products and/or services of BBVA API Market through electronic means.
For how long we will keep your data?
We will keep your data as long as necessary for the management of your request, and to receive commercial communications, events and surveys. BBVA will keep your data until you unsubscribe to stop receiving our newsletters or, where appropriate, until the end of the service. Afterwards, we will destroy your data.
How can I unsubscribe to stop receiving newsletters and/or communications from BBVA API Market?
You can unsubscribe at any time and without need to indicate any justification, by sending an email to the following address: contact.bbvaapimarket@bbva.com
To whom will we communicate your data?
We will not transfer your personal data to third parties, unless it is mandatory by a law or if you have previously agreed to do so.
What are your rights when you provide us with your information?
You will be able to consult your personal data included in BBVA files (access right)
You can modify your personal data when they are inaccurate (correction right)
You may request that your personal data not be processed (opposition right)
You may request your personal data be deleted (suppression right)
You can request a limitation on the processing of your data in the allowed cases (right of limitation of processing)
You will be able to receive, in electronic format, the personal data you have provided to us, as well as to transmit them to another entity (portability right)
You can exercise before BBVA the aforementioned rights through the following address: contact.bbvaapimarket@bbva.com
You are responsible for the accuracy of the personal data you provide to BBVA and to keep them duly updated.
If you believe that we have not processed your personal data in accordance with the regulations, you can contact the Data Protection Officer at the following address: dpogrupobbva@bbva.com
You can find more information in the “Personal Data Protection Policy” document on this website.
Banco Bilbao Vizcaya Argentaria, S.A. owner of this portal uses cookies and/or similar technologies of its own and third parties for the purposes of personalization, analytics, behavioral advertising or advertising related to your preferences based on a profile prepared from your browsing habits (e.g. pages visited). If you wish to obtain more detailed information, consult our Cookies Policy.
Cookie settings panel
These are the advanced settings for first-party and third-party cookies. Here you can change the parameters that will affect your browsing experience on this website.
Technical Cookies (required)
These cookies are used to give you secure access to areas with personal information and to identify you when you log in.
Name
Owner
Duration
Description
gobp.lang
BBVA
1 month
Language preference
aceptarCookies
BBVA
1 year
Configuration Accepted Cookies
_abck
BBVA
1 year
Helps protect against malicious website attacks
bm_sz
BBVA
4 hours
Helps protect against malicious website attacks
ADRUM_BTs
Salesforce Marketing Cloud
Session
Required for monitoring of the service, inherent to SFMC
ADRUM_BT1
Salesforce Marketing Cloud
Session
Required for monitoring of the service, inherent to SFMC
ADRUM_BTa
Salesforce Marketing Cloud
Session
Required for monitoring of the service, inherent to SFMC
ADRUM_BT
Salesforce Marketing Cloud
Session
Required for monitoring of the service, inherent to SFMC
xt_0d95e
Salesforce Marketing Cloud
Session
Remember user preferences (if any)
__s9744cdb192d044faa1bf201d29fafd1e
Salesforce Marketing Cloud
Session
Remember user preferences (if any)
wpml_browser_redirect_test
WPML
Session
Text translation in the portal
wp-wpml_current_language
WPML
24 hours
Text translation in the portal
They are used to track the activity or number of visits anonymously. Thanks to them we can constantly improve your browsing experience
Your browsing experience is constantly improving.
With your selection, we cannot offer you a continuously improved browsing experience.
Name
Owner
Duration
Description
AMCV_***
Adobe Analytics
Session
Unique Visitor IDs used in Cloud Marketing solutions
AMCVS_***
Adobe Analytics
2 years
Unique Visitor IDs used in Cloud Marketing solutions
demdex (safari)
Adobe Analytics
180 days
Create and store unique and persistent identifiers
sessionID
Adobe Analytics
Session
Launch's internal cookie used to identify the user
gpv_URL
Adobe Analytics
Session
Adobe Analytics plugin: getPreviousValue Capture the value of a certain variable in the following page view, in this case the prop1
gpv_level1
Adobe Analytics
Session
Cookie used to store the DataLayer levl1 of the previous page.
gpv_pageIntent
Adobe Analytics
Session
Cookie used to store the pageIntent of the previous page.
gpv_pageName
Adobe Analytics
Session
Cookie used to store the pagename of the previous page.
aocs
Adobe Analytics
Session
Cookie that stores the first values collected at the beginning of a process.
TTC
Adobe Analytics
Session
Cookie used to store the time between the App Page Visit event and the App Completed event.
TTCL
Adobe Analytics
Session
Cookie used to store the time between the LogIn event and App Completed.
s_cc
Adobe Analytics
Session
Determine if cookies are active
s_hc
Adobe Analytics
Session
Cookie used by Adobe for analytical purposes
s_ht
Adobe Analytics
Session
Cookie used by Adobe for analytical purposes
s_nr
Adobe Analytics
2 years
Determine the number of user visits
s_ppv
Adobe Analytics
Permanent
Adobe Analytics plugin: getPercentPageViewed Determine what percentage of the page a user views
s_sq
Adobe Analytics
Session
ClickMap/ActivityMap features
s_tp
Adobe Analytics
Session
Cookie used by Adobe for analytical purposes
s_visit
Adobe Analytics
2 years
Cookie used by Adobe to know when a session has been started.
They allow the advertising shown to you to be customized and relevant to you. Thanks to these cookies, you will not see ads that you are not interested in.
The advertising is customized to you and your preferences.
Your choice means you will not see customized ads, only generic ones.
Name
Owner
Duration
Description
OT2
VersaTag
90 days
VersaTag Cookie used to store a user id and the number of user visits.
u2
VersaTag
90 days
VersaTag Cookie where the user ID is stored
TargetingInfo 2
MediaMind
1 year
Cookie that serves to assign a unique random number that generates MediaMind.
These cookies are related to general features such as the browser you use.
Your experience and content have been customized.
With your selection, we cannot offer you a continuously improved browsing experience.
Name
Owner
Duration
Description
mbox
Adobe Target
9 days
Cookie used by Adobe Target to test user experience customization.
×
Looks like you’re browsing from Mexico, so let’s show you the custom content for your
location. Change
Looks like you’re browsing from Spain, so let’s show you the custom content for your
location. Change
Select a country
In order to access the private area and corresponding sandbox, select the country of the APIs you want to use.