
In the world of Big Data, new technology enriches the Hadoop ecosystem almost every month. However, this can also confuse new starters as there so many types of software, and it is not possible to remember them all. Nevertheless, over the last few months Spark has neither been forgotten nor lost strength, and is now a Big Data star technology.
At Pragsis we have been testing this new Hadoop component for some time. However, last week I attended Cloudera's three-day course (to be included in Pragsis training range soon), and got to know this company in more depth. As a result, my opinion of Spark is now even more positive.

Spark will bring a change to the world of Big Data
Spark offers many advantages when compared to MapReduce-Hadoop:
– Big Data “in-memory”
Spark's most visible facet. Let's forget about SAP-Hana and other ("expensive") proprietary solutions. Spark performs parallel jobs totally in memory, hence greatly reducing processing times. This is especially relevant if we talk about iterative processes such as Machine Learning processes. Below you can see the benchmark found at https://spark.apache.org/, which compares Spark's with Hadoop-MapReduce's performance.
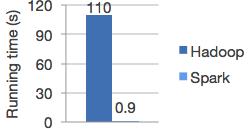
Working in memory does not mean that we need to buy servers with terabytes of RAM; and this represents a step away from Hadoop's “commodity hardware”. If some data cannot be stored in memory, Spark keeps working and uses the hard disk to store the data that are unnecessary at any given time. Programmers can also set priorities, and specify which data must always be in memory.
– More flexible computing schema vs. MapReduce
I have always disliked MapReduce's little flexibility in terms of creating data flows. You can only create a “Map -> Shuffle -> Reduce” schema. Sometimes it would be interesting to create a “Map -> Shuffle -> Reduce -> Shuffle -> Reduce” schema but, with MapReduce, you need to create a “job 1(Map -> Shuffle -> Reduce) ; job 2 (Map -> Shuffle -> Reduce)” flow, which forces you to include a Map "identity" phase with no purpose other than wasting time. In order to optimize this, the Tez framework was created to replace “MapShuffleReduce” with a directed acyclic graph (DAG) flow of execution:
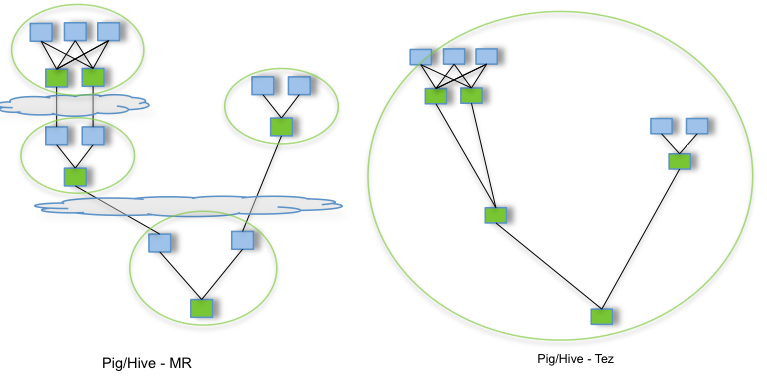
Spark is also aware of this limitation and, as with Tez, suggests DAG-based workflows. Processing times are further reduced.
– Real-time streaming and batch unification
This is another very important issue for Big Data. Attempts to create mechanisms that provide Hadoop with a real-time component have been made for years (framework initially oriented toward batch processes). There have been several proposals (HBase, Impala, Flume, etc.) but they only partially meet this need for real time and stream processing. Then, we had the famous “lambda” and “kappa”. Spark simplifies all this by allowing work both in batch and real-time stream modes. The same framework for two worlds.

– A very flexible way of working
Spark provides an API for Java, and Python and Scala: no esoteric languages that are only compatible with one technology (such as Pig Latin). Python and Scala can also be used in scripting mode: no time is wasted with iterations such as "edit, build and run program". You only have to run the commands in a Spark interpreter to be able to use the data in our cluster. This makes “Data Discovery” much easier (see last section of this article).
Additionally, you can write a whole application on Python, Java or Scala (this is the best language in terms of performance and use of every Spark feature), build it and run it in the cluster.
– A much more complete ecosystem
As with MapReduce, Spark acts as a base framework on which a growing number of increasingly advanced applications is developed.Currently there is:- Spark SQL: explore data with SQL language- Spark Streaming: mentioned above – MLib: libraries for Machine Learning- GraphX: for graph computing
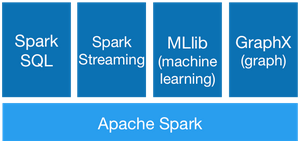
I guess this software sounds quite similar to Hive, Mahout and Giraph on Hadoop. Given how often Spark is adopted and its appeal to many key companies in the Big Data (Yahoo, Facebook, etc.) industry, I have no doubt that this ecosystem will grow in the next few months.
For these reasons, it's not surprising that many people see Spark as the future of Hadoop. “MapReduce has no advantage over Spark” was often repeated during Cloudera's course.
Spark is not stable and is not ready for production yet
Spark seems promising. But this sentence by Cloudera needs to be put into perspective. In fact, Cloudera's staff went on to say that Spark is still a young software without the same stability as Hadoop-MapReduce. For example, during the exercises the students found a bug in Spark, and the course trainer opened an incident straight away. This had never happened before…
Another important detail: Cloudera did confirm that some of its clients are using Spark but none of them are using it in production mode.
Spark progresses very fast: in one year it went from version 0.7 to version 1.0. This is really good because it means that a lot of improvements are added, and the project is very much alive. However, so many version changes also reflect some lack of maturity and, consequently, stability.
Another example is the sudden diversity of SQL solutions on Hadoop:
– First, there was Hive.
– Cloudera launched Impala to provide "real time" on Hadoop.
– Hortonworks developed Stinger to improve Hive and compete against Impala.
– Shark was developed over Spark as a “Hive in memory”.
– Databricks stopped supporting Shark and decided to refactor everything in a new project: SparkSQL.
– There is a new Hive initiative built on Spark. It seems Cloudera is relatively supportive of this new project, which shows Hortonworks that promoting Impala was a mistake.
This tangle of SQL solutions on Hadoop is not surprising for this type of very innovative technologies. In fact, I think that such a high number of projects encourages competitiveness and is a good thing…at first. Later, as with any software, there must be consolidation with only two (or maybe three) key SQL solutions left. So there is no reason to rush.
In short, Spark is a technology with a lot of potential. But at present I would not recommend that you put a lot of effort into it, or that you try to develop very advanced applications and move solutions to production.
What should we do now? Testing and data discovery
Spark is not sufficiently mature for a production environment. Does this mean that we shouldn't use it now? Of course not.
Firstly, testing this new technology is very important for many technology companies. Since Spark will replace MapReduce, any Big Data company that wants to retain its leading position cannot ignore Spark. Pragsis is every aware of this. For this reason, we have been testing this technology for months (without major developments; see previous section).
Secondly, I do believe that this technology is a very important addition to “Data Discovery”. Spark is a very valuable tool in terms of exploring data interactively for several reasons: it can be used in scripting mode; it allows extraction of information from HDFS; it has very good scalable processing capacity; and it includes a very advanced API linked to machine learning libraries. In fact, Spark is a lot more valuable than Pig, which was once regarded as a possibility for data discovery.
Additionally, Data Discovery is a very interactive process that is often found at the beginning of some projects. Consequently, we are far from an "in production" deployment. And, to this extent, Spark's lack of stability is no problem at all.








